Spark Shell is an interactive shell through which we can access Spark’s API. Spark provides the shell in two programming languages : Scala and Python. In this tutorial, we shall learn the usage of Python Spark Shell with a basic word count example.
Python Spark Shell
Prerequisites
Prerequisite is that Apache Spark is already installed on your local machine. If not, please refer Install Spark on Ubuntu or Install Spark on MacOS based on your Operating System.
Start Spark Interactive Python Shell
Python Spark Shell can be started through command line. To start pyspark, open a terminal window and run the following command:
~$ pyspark
For the word-count example, we shall start with option–master local[4] meaning the spark context of this spark shell acts as a master on local node with 4 threads.
~$ pyspark --master local[4]
If you accidentally started spark shell without options, you may kill the shell instance.
~$ pyspark --master local[4]
Python 2.7.12 (default, Nov 19 2016, 06:48:10)
[GCC 5.4.0 20160609] on linux2
Type "help", "copyright", "credits" or "license" for more information.
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
17/11/13 12:10:21 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/11/13 12:10:22 WARN Utils: Your hostname, tutorialkart resolves to a loopback address: 127.0.0.1; using 192.168.0.104 instead (on interface wlp7s0)
17/11/13 12:10:22 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address
17/11/13 12:10:40 WARN ObjectStore: Failed to get database global_temp, returning NoSuchObjectException
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 2.2.0
/_/
Using Python version 2.7.12 (default, Nov 19 2016 06:48:10)
SparkSession available as 'spark'.
>>> 
Spark context Web UI would be available at http://192.168.0.104:4040 [The default port is 4040]. Open a browser and hit the url http://192.168.0.104:4040.
Spark context : You can access the spark context in the shell as variable named sc.
Spark session : You can access the spark session in the shell as variable named spark.
Word-Count Example with PySpark
We shall use the following Python statements in PySpark Shell in the respective order.
input_file = sc.textFile("/path/to/text/file")
map = input_file.flatMap(lambda line: line.split(" ")).map(lambda word: (word, 1))
counts = map.reduceByKey(lambda a, b: a + b)
counts.saveAsTextFile("/path/to/output/") Input
In this step, using Spark context variable, sc, we read a text file.
input_file = sc.textFile("/path/to/text/file") Map
We can split each line of input using space ” ” as separator.
flatMap(lambda line: line.split(" ")) and we map each word to a tuple (word, 1), 1 being the number of occurrences of word.
map(lambda word: (word, 1))
We use the tuple (word,1) as (key, value) in reduce stage.
Reduce
Reduce all the words based on Key. Here a, b are values and for the same key, values are reduced to a+b.
counts = map.reduceByKey(lambda a, b: a + b)
Save counts to local file
At the end, counts could be saved to a local file.
counts.saveAsTextFile("/path/to/output/") When all the commands are run in Terminal, following would be the output :
>>> input_file = sc.textFile("/home/arjun/data.txt")
>>> map = input_file.flatMap(lambda line: line.split(" ")).map(lambda word: (word, 1))
>>> counts = map.reduceByKey(lambda a, b: a + b)
>>> counts.saveAsTextFile("/home/arjun/output/")
>>> Output can be verified by checking the save location.
/home/arjun/output$ls part-00000 part-00001 _SUCCESS
Sample of the contents of output file, part-00000, is shown below :
/home/arjun/output$cat part-00000 (branches,1) (sent,1) (mining,1) (tasks,4)
We have successfully counted unique words in a file with the help of Python Spark Shell – PySpark.
You can use Spark Context Web UI to check the details of the Job (Word Count) we have just run.
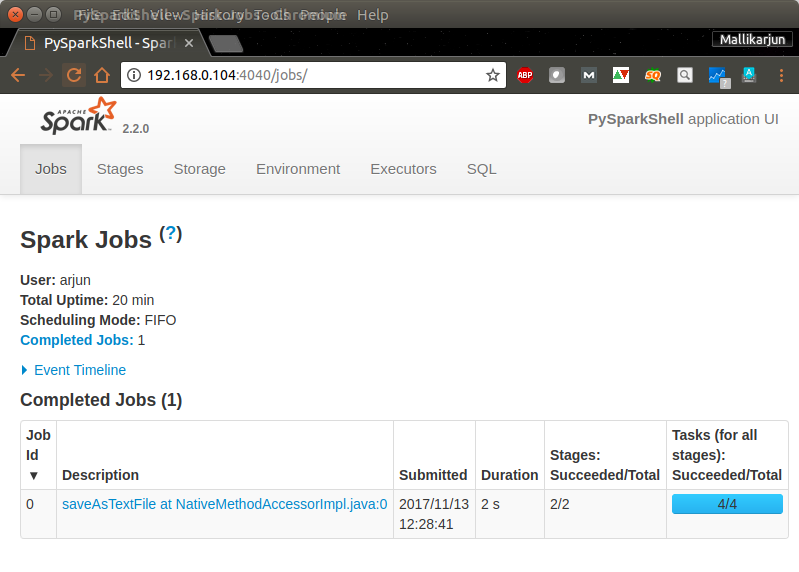
Navigate through other tabs to get an idea of Spark Web UI and the details about the Word Count Job.
Conclusion
In this Apache Spark Tutorial, we have learnt the usage of Spark Shell using Python programming language with the help of Word Count Example.