Apache Hadoop Tutorial – We shall learn to install Apache Hadoop on Ubuntu. Java is a prerequisite to run Hadoop.
Install Apache Hadoop on Ubuntu
Following is a step by step guide to Install Apache Hadoop on Ubuntu
Install Java
Hadoop is an open-source framework written in Java. So, for Hadoop to run on your computer, you should install Java in prior.
Open a terminal and run the following command :
$ sudo apt-get install default-jdkTo verify the installation of Java, run the following command in the terminal :
$ java -versionThe output for the command would be as shown below.
hadoopuser@tutorialkart:~# java -version
openjdk version "1.8.0_131"
OpenJDK Runtime Environment (build 1.8.0_131-8u131-b11-0ubuntu1.16.04.2-b11)
OpenJDK 64-Bit Server VM (build 25.131-b11, mixed mode)Install Hadoop
Download latest Hadoop binary package from http://hadoop.apache.org/releases.html.
Look for latest stable release (not in alpha channel) and click on binary link provided for the release.
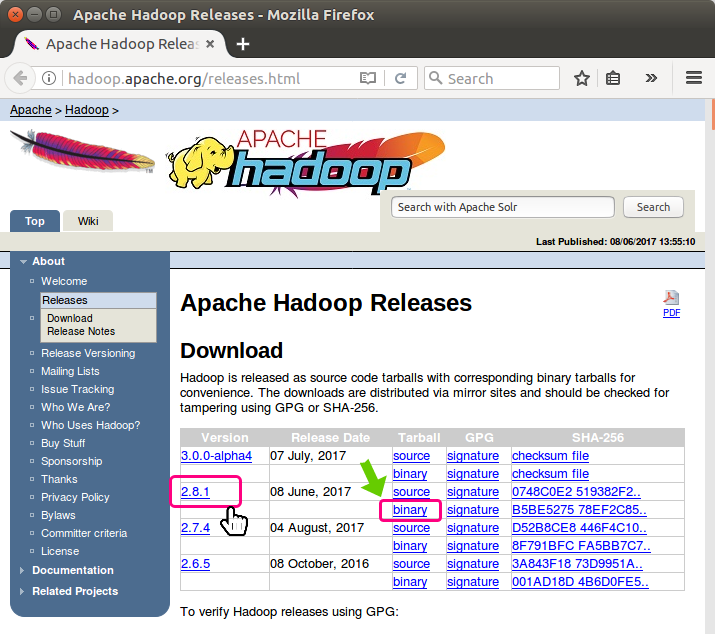
Click on the first mirror link

Copy the downloaded tar file to /usr/lib/ and untar.
$ sudo cp hadoop-2.8.1.tar.gz /usr/lib/
$ sudo tar zxf hadoop-2.8.1.tar.gz
$ sudo rm hadoop-2.8.1.tar.gzProvide the password if asked.
Set Java and Hadoop Path
Make sure you have the PATHs set up for Java and Hadoop in bashrc file.
Open a Terminal and run the following command to edit bashrc file.
$ sudo nano ~/.bashrcPaste the following entries at the end of .bashrc file.
#HADOOP VARIABLES START
export JAVA_HOME=/usr/lib/jvm/default-java/jre
export HADOOP_INSTALL=/usr/lib/hadoop-2.8.1
export PATH=$PATH:$HADOOP_INSTALL/bin
export PATH=$PATH:$HADOOP_INSTALL/sbin
export HADOOP_MAPRED_HOME=$HADOOP_INSTALL
export HADOOP_COMMON_HOME=$HADOOP_INSTALL
export HADOOP_HDFS_HOME=$HADOOP_INSTALL
export YARN_HOME=$HADOOP_INSTALL
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_INSTALL/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_INSTALL/lib"
#HADOOP VARIABLES END Run Hadoop
After setting up the path for Hadoop and Java, you may run the hadoop command, from anywhere, using the terminal.
$ hadoopThe output would be as shown below :
Usage: hadoop [--config confdir] [COMMAND | CLASSNAME]
CLASSNAME run the class named CLASSNAME
or
where COMMAND is one of:
fs run a generic filesystem user client
version print the version
jar run a jar file
note: please use "yarn jar" to launch
YARN applications, not this command.
checknative [-a|-h] check native hadoop and compression libraries availability
distcp copy file or directories recursively
archive -archiveName NAME -p * create a hadoop archive
classpath prints the class path needed to get the
Hadoop jar and the required libraries
credential interact with credential providers
daemonlog get/set the log level for each daemon
trace view and modify Hadoop tracing settings
Most commands print help when invoked w/o parameters.Conclusion
In this Apache Hadoop Tutorial, we have successfully installed Hadoop on Ubuntu. In subsequent tutorials, we shall look into HDFS and MapReduce and start with Word Count Example in Hadoop.