Apache Kafka Architecture
Apache Kafka Architecture – We shall learn about the building blocks of Kafka : Producers, Consumers, Processors, Connectors, Topics, Partitions and Brokers.
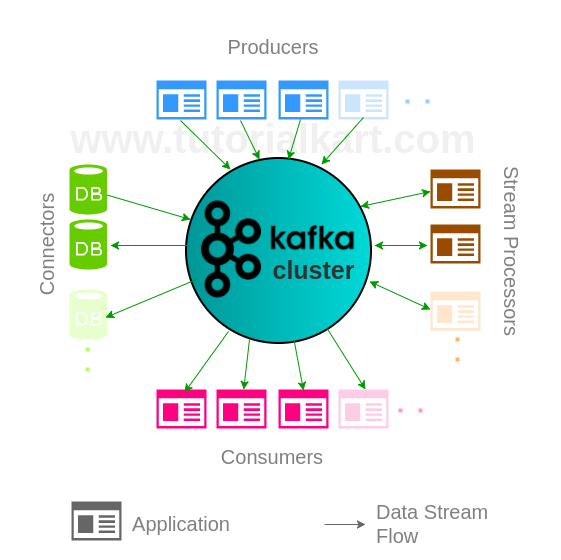
A typical Kafka cluster comprises of data Producers, data Consumers, data Transformers or Processors, Connectors that log changes to records in a Relational DB. We shall learn more about these building blocks in detail in our following tutorial.
Life cycle of an Entry (or Record) in Kafka Cluster
Now we shall see the journey of an entry through different blocks in a cluster.
A record is created by a Producer and is written to one of the existing Topics in Kafka cluster or a new Topic is created and written to it. The record in the Topic is waiting for the Consumer or Stream Processor. Consider that a Stream Processor has subscribed to the Topic. Our Entry might join some other records in the partition and read by the Stream Processor. The Processor now may transform the record into a new record or enrich it and write back to the cluster into a new Topic. There could be multiple transformations by multiple Stream Processors on the record. Now consider that after a long journey the transformed Record has come to a Topic called TheLastTopic. And also consider that a consumer has subscribed to this Topic “TheLastTopic”. Consumer consumes the record from this Topic and the record has been used up. In the journey of the record, the changes happening to the record may be logged into Relational Databases using Connectors.
Any application can become a Producer, Consumer or Stream Processor based on the role it plays in the Cluster. Kafka Cluster is flexible on how an application wants to connect to it.
Kafka Producer
Producer is an application that generates the entries or records and sends them to a Topic in Kafka Cluster.
- Producers are source of data streams in Kafka Cluster.
- Producers are scalable. Multiple producer applications could be connected to the Kafka Cluster.
- A single producer can write the records to multiple Topics [based on configuration].
Java Example for Apache Kafka Producer
Kafka Consumer
Consumer is an application that feed on the entries or records of a Topic in Kafka Cluster.
- Consumers are sink to data streams in Kafka Cluster.
- Consumers are scalable. Multiple consumer applications could be connected to the Kafka Cluster.
- A single consumer can subscribe to the records of multiple Topics [based on configuration].
Kafka Stream Processors
Stream Processor is an application that enrich/transform/modify the entries or records of a Topic (sometimes write these modified records to a new Topic) in Kafka Cluster.
- Stream Processors first act as sink and then as source in Kafka Cluster.
- Stream Processors are scalable. Multiple Stream Processing applications could be connected to the Kafka Cluster.
- A single Stream Processor can subscribe to the records of multiple Topics [based on configuration] and then write records back to multiple Topics.
Kafka Connector
Connectors are those which allow the integration of things like Relational Databases to the Kafka Cluster and automatically monitor the changes. They also help to pull those changes onto the Kafka cluster.
Connectors provide a single source of ground truth data. Which means that we have a record of changes, a Topic has undergone.
Brokers, Topics and their Partitions – in Apache Kafka Architecture
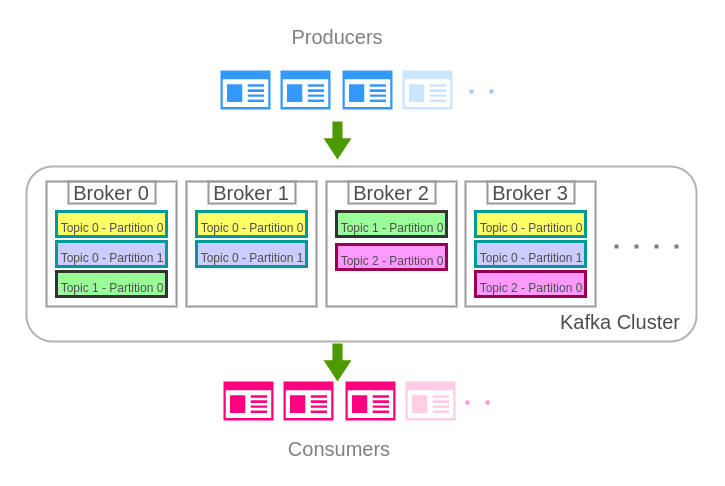
Observe in the following diagram that there are three topics. Topic 0 has two partitions, Topic 1 and Topic 2 has only single partition. Topic 0 has a replication factor or 3, Topic 1 and Topic 2 have replication factor of 2. Zookeeper may elect any of these brokers as a leader for a particular Topic Partition.
Kafka Broker
Brokers are logical separation of tasks happening in a Kafka Cluster.
- Brokers could be on multiple machines.
- Multiple brokers could be on a single machine.
- A Broker can handle some of the [partitions in] Topics and is responsible for those.
- Multiple backups of Topic Partitions are created in multiple brokers based on the number of replications you provide during the creation of a Topic.
- Brokers containing the backups of a Topic Partition help in balancing the load. [Load is the number of applications connected to the broker either for read or write operations or both.]
- If a Broker goes down, one of the Broker containing the backup partitions would be elected as a leader for the respective partitions. And thus Kafka is resilient.
Kafka Topic
Topic is a logical collection of records that are assumed to fall into a certain category.
- A Topic can be created with multiple partitions by considering the load or distribution of read/write sources (producers/consumers/processors).
- Number of Partitions a Topic could be divided is provided during the creation of the Topic.
Conclusion :
We have learnt the Apache Kafka Architecture and its components in detail.