Fix NLTK LookupError: Downloading Missing NLTK Resources
The LookupError in Natural Language Toolkit (NLTK) occurs when the required resources (such as tokenizers, corpora, or models) are missing. A common solution is to download all NLTK resources at once using:
import nltk
nltk.download('all')This tutorial provides a step-by-step guide to resolving NLTK’s LookupError by ensuring all necessary resources are installed.
Understanding the NLTK LookupError
Why does this error occur?
When using functions like nltk.word_tokenize() or nltk.sent_tokenize(), NLTK relies on pre-trained tokenizers stored in its data directory. If the required resources are missing, you will encounter a LookupError similar to this:
LookupError:
**********************************************************************
Resource 'punkt' not found.
Please use the NLTK Downloader to obtain the resource:
>>> import nltk
>>> nltk.download('punkt')
For more information see: https://www.nltk.org/data.html
**********************************************************************This happens because NLTK does not include all resources by default. You need to manually download the required packages.
Solution: Download All NLTK Packages
Instead of downloading each package individually, you can install all available NLTK resources at once using:
Step 1: Open Python or Jupyter Notebook
Ensure you have Python installed. Open a Python environment (Terminal, Command Prompt, or Jupyter Notebook).
Step 2: Run the Following Command
import nltk
nltk.download('all')This command will:
- Download all tokenizers, corpora, and models required for various NLP tasks.
- Store them in your local
nltk_datadirectory. - Prevent further
LookupErrorissues.
Verifying the Installation
After running nltk.download('all'), verify that NLTK can access the required resources.
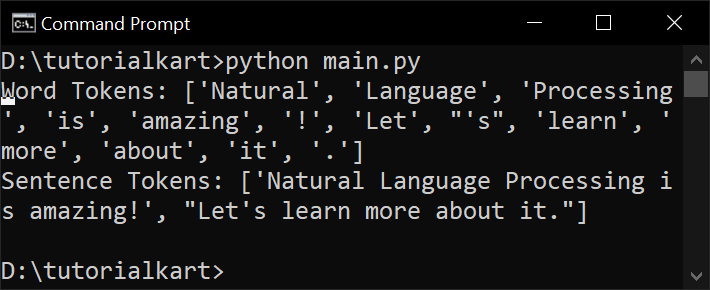
Example: Tokenization Test
Run the following script:
from nltk.tokenize import word_tokenize, sent_tokenize
text = "Natural Language Processing is amazing! Let's learn more about it."
tokens = word_tokenize(text)
sentences = sent_tokenize(text)
print("Word Tokens:", tokens)
print("Sentence Tokens:", sentences)If the script runs without errors, the issue is resolved.