What is Stemming in NLP?
Stemming is the process of reducing a word to its base or root form. The idea is to remove prefixes and suffixes to get the stem of a word.
For example:
- Running → Run
- Played → Play
- Happily → Happi
Notice that the word “Happily” was reduced to “Happi”. This is because stemming often results in words that may not be actual dictionary words. It only removes known prefixes or suffixes based on rules.
Why is Stemming Important?
In NLP, words like “run”, “running”, and “ran” have similar meanings. Instead of treating them as separate words, we can reduce them to a common root to reduce the vocabulary size.
Applications of stemming include:
- Search Engines – Searching for “running” should also return results for “run”.
- Text Classification – Helps categorize similar words under one group.
- Sentiment Analysis – “happy” and “happiness” should be treated similarly.
Types of Stemming Algorithms
There are different algorithms for stemming. Each has its own way of reducing words to their base forms.
1 Porter Stemmer
The Porter Stemmer is one of the most commonly used stemming algorithms. It applies a series of rules to strip suffixes in multiple steps.
Example: main.py
from nltk.stem import PorterStemmer
stemmer = PorterStemmer()
words = ["running", "flies", "happiness", "playing", "easily"]
stems = [stemmer.stem(word) for word in words]
print(stems)Output:
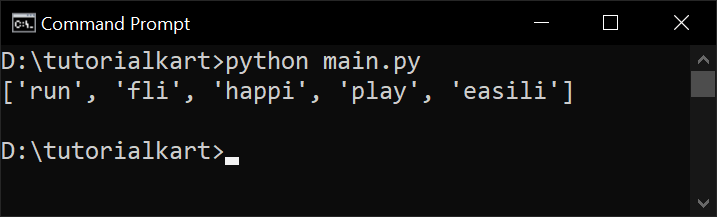
Explanation:
- “running” → “run” (removes “ing”)
- “flies” → “fli” (removes “es”, but the stem is not a real word)
- “happiness” → “happi” (not a perfect reduction)
- “playing” → “play”
- “easily” → “easili” (not a real word, but useful for NLP tasks)
The Porter Stemmer is fast and widely used, but sometimes produces non-dictionary words.
2 Snowball Stemmer (Porter2)
The Snowball Stemmer is an improved version of the Porter Stemmer and supports multiple languages.
Example: main.py
from nltk.stem import SnowballStemmer
stemmer = SnowballStemmer("english")
words = ["running", "flies", "happiness", "playing", "easily"]
stems = [stemmer.stem(word) for word in words]
print(stems)Output:
Compared to the Porter Stemmer, the Snowball Stemmer produces better results.
3 Lancaster Stemmer
The Lancaster Stemmer is more aggressive than the Porter Stemmer. It reduces words aggressively and may sometimes over-stem words.
Example: main.py
from nltk.stem import LancasterStemmer
stemmer = LancasterStemmer()
words = ["running", "flies", "happiness", "playing", "easily"]
stems = [stemmer.stem(word) for word in words]
print(stems)Output:
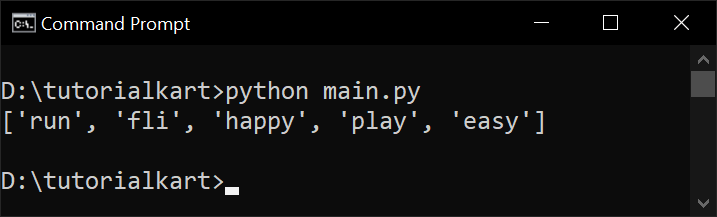
The Lancaster Stemmer sometimes reduces words too much, resulting in stems that are hard to interpret.
4 Regex-Based Stemming
Instead of using predefined rules, you can create custom stemming rules using regular expressions.
Example: main.py
import re
def simple_stem(word):
return re.sub(r"(ing|ly|ed|es|s)$", "", word)
words = ["running", "happily", "played", "flies", "jumps"]
stems = [simple_stem(word) for word in words]
print(stems)Output:
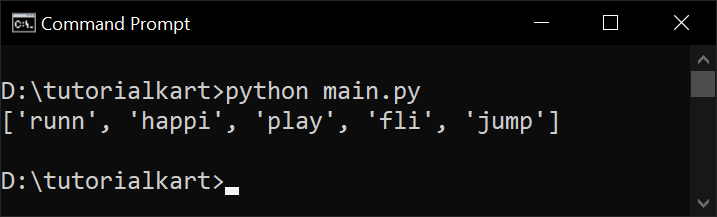
While this approach is simple, it does not handle all cases well.
Comparison of Stemming Algorithms
| Algorithm | Pros | Cons |
|---|---|---|
| Porter Stemmer | Simple, widely used | Sometimes removes too much |
| Snowball Stemmer | Improved version of Porter, supports multiple languages | Still produces non-dictionary words |
| Lancaster Stemmer | Very aggressive | Can over-stem words |
| Regex-Based | Customizable | Doesn’t handle all words |
Stemming vs. Lemmatization
Stemming is often confused with lemmatization, but they are different.
| Feature | Stemming | Lemmatization |
|---|---|---|
| Method | Removes suffixes | Uses dictionary lookup |
| Result | May not be a real word | Always a valid word |
| Example | Happiness → Happi | Happiness → Happy |
If high accuracy is needed, lemmatization is preferred over stemming.
When to Use Stemming?
- When speed is more important than accuracy (e.g., search engines).
- When working with informal text (e.g., tweets, reviews).
- When reducing word forms quickly for keyword-based NLP tasks.
Conclusion
Stemming is a fundamental NLP technique used to normalize words. Different algorithms exist, each with strengths and weaknesses. While stemming is useful, it is often used with other NLP techniques like lemmatization, tokenization, and vectorization.