1 Introduction to Stop-words
Stop-words are commonly used words in a language that do not contribute significantly to the meaning of a sentence. They serve grammatical purposes but carry little useful information for NLP tasks like text classification or information retrieval.
For example, consider the sentence:
"The sun is shining brightly in the sky."Here, words like “the”, “is”, “in”, “the” are stop-words, while “sun”, “shining”, “brightly”, “sky” are more meaningful words that help determine the sentence’s intent.
2 Why Remove Stop-words?
Removing stop-words is crucial for various NLP applications because:
- Reduces dimensionality: Eliminating unnecessary words reduces the overall data size, making processing faster.
- Improves accuracy: Many NLP models perform better without stop-words since they focus on meaningful words.
- Enhances text analysis: Helps extract important keywords for sentiment analysis, topic modeling, and text classification.
Example before and after stop-word removal:
| Original Sentence | After Stop-word Removal |
|---|---|
| “The cat is sitting on the mat.” | “cat sitting mat” |
| “She is going to the market to buy some apples.” | “She going market buy apples” |
3 Common Stop-word Lists
Every language has its own set of stop-words. Popular NLP libraries like NLTK, SpaCy, and Scikit-learn provide predefined stop-word lists.
English Stop-word Examples:
- Articles: a, an, the
- Pronouns: he, she, it, they
- Prepositions: in, on, at, over
- Conjunctions: and, but, or
- Auxiliary Verbs: is, am, are, was, were
Stop-words in Other Languages:
Different languages have different stop-words. Some examples:
- French: le, la, les, un, une, et, ou
- Spanish: el, la, los, de, que, y
- German: der, die, das, und, zu, mit
4 Handling Stop-words in NLP
4.1. Removing Stop-words Using NLTK
NLTK provides a built-in stop-word list for English and other languages. Below is an example of removing stop-words using NLTK in Python.
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
nltk.download('stopwords')
nltk.download('punkt')
text = "This is an example sentence showing stop-word removal."
words = word_tokenize(text)
filtered_words = [word for word in words if word.lower() not in stopwords.words('english')]
print(filtered_words)Output:
['example', 'sentence', 'showing', 'stop-word', 'removal', '.']4.2. Removing Stop-words Using SpaCy
SpaCy provides an efficient way to handle stop-words in NLP.
Run the following command in your command prompt or terminal to install en_core_web_sm model.
python -m spacy download en_core_web_smmain.py
import spacy
nlp = spacy.load("en_core_web_sm")
text = "This is an example sentence showing stop-word removal."
doc = nlp(text)
filtered_words = [token.text for token in doc if not token.is_stop]
print(filtered_words)Output:
['example', 'sentence', 'showing', 'stop', '-', 'word', 'removal', '.']4.3. Removing Stop-words Using Scikit-learn
Scikit-learn also has a predefined stop-word list.
Run the following pip command to install scikit-learn.
pip install scikit-learnmain.py
from sklearn.feature_extraction.text import ENGLISH_STOP_WORDS
text = "This is an example sentence showing stop-word removal."
words = text.split()
filtered_words = [word for word in words if word.lower() not in ENGLISH_STOP_WORDS]
print(filtered_words)Output:
['example', 'sentence', 'showing', 'stop-word', 'removal.']5 Customizing Stop-word Removal
5.1. Adding Custom Stop-words
Sometimes, default stop-word lists may not fit specific tasks, and you may need to add domain-specific words.
Run the following pip command to install scikit-learn.
main.py
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
# Download stopwords and tokenizer if not already downloaded
nltk.download('stopwords')
nltk.download('punkt')
custom_stopwords = set(stopwords.words('english'))
custom_stopwords.update(["example", "showing"])
text = "This is an example sentence showing stop-word removal."
words = word_tokenize(text)
filtered_words = [word for word in words if word.lower() not in custom_stopwords]
print(filtered_words)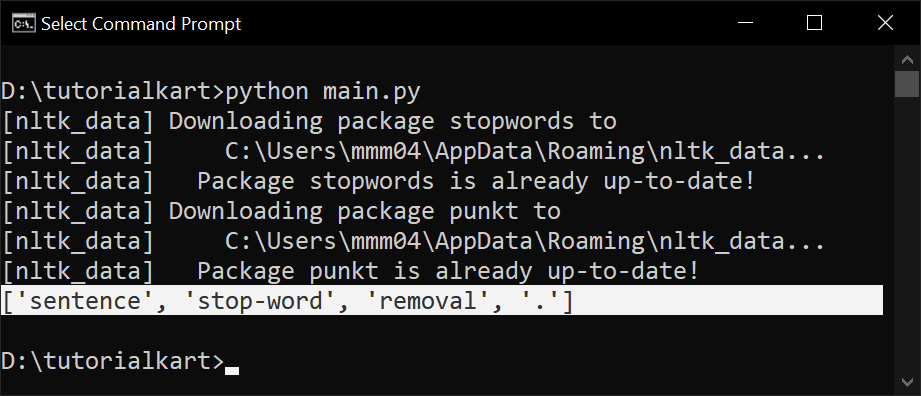
5.2. Removing Certain Stop-words
In some NLP tasks, certain stop-words like “not” or “but” may be important. You can remove them from the stop-word list.
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
# Download stopwords and tokenizer if not already downloaded
nltk.download('stopwords')
nltk.download('punkt')
text = "This is an example sentence, but there is not another."
words = word_tokenize(text)
stop_words = set(stopwords.words('english'))
stop_words.discard('not') # Keeping 'not' for sentiment analysis
filtered_words = [word for word in words if word.lower() not in stop_words]
print(filtered_words)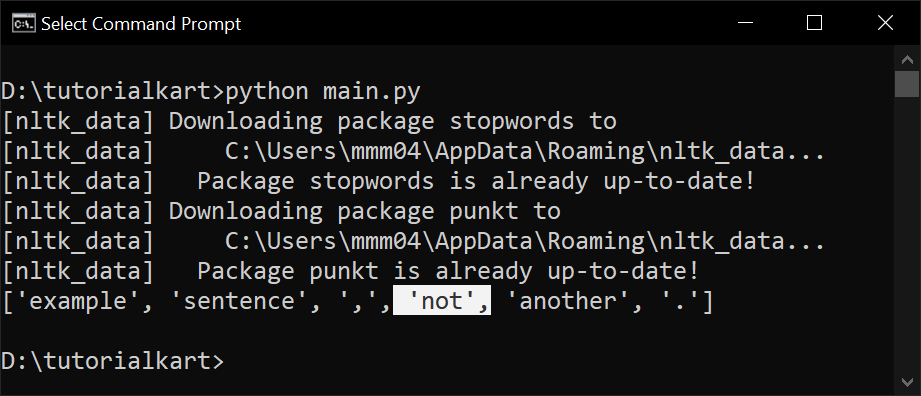
6 Challenges in Stop-word Removal
Although removing stop-words is useful, there are certain challenges:
- Loss of Context: Some stop-words carry meaning in specific cases, e.g., “not” in sentiment analysis.
- Language Variability: Different languages require different stop-word lists.
- Domain-Specific Needs: A financial text may have different stop-words than a medical document.
7 When Not to Remove Stop-words?
Stop-word removal is useful for many NLP tasks but should be avoided in some cases:
- Sentiment Analysis: Words like “not” can reverse the meaning (e.g., “not happy” ≠ “happy”).
- Text Generation: Keeping stop-words helps in generating natural sentences.
- Machine Translation: Stop-words play a crucial role in correct sentence structure.
8 Conclusion
Stop-word removal is a fundamental step in text preprocessing that helps in reducing text size and improving NLP model performance. However, it should be applied thoughtfully based on the use case.
Key Takeaways:
- Stop-words are common words that do not add significant meaning.
- Removing them improves efficiency and accuracy in NLP tasks.
- Different libraries like NLTK, SpaCy, and Scikit-learn provide built-in stop-word lists.
- Customizing stop-words is necessary for certain applications.
In the next tutorial, we will explore Stemming and Lemmatization, which help in reducing words to their root form.