A new Java Project can be created with Apache Spark support. For that, jars/libraries that are present in Apache Spark package are required. The path of these jars has to be included as dependencies for the Java Project.
In this tutorial, we shall look into how to create a Java Project with Apache Spark having all the required jars and libraries. We use Eclipse as IDE to work with the project used for demonstration in the following example. The process should be same with other IDEs like IntelliJ IDEA, NetBeans, etc.
As a prerequisite, Java and Eclipse had to be setup on the machine.
Eclipse – Create Java Project with Apache Spark
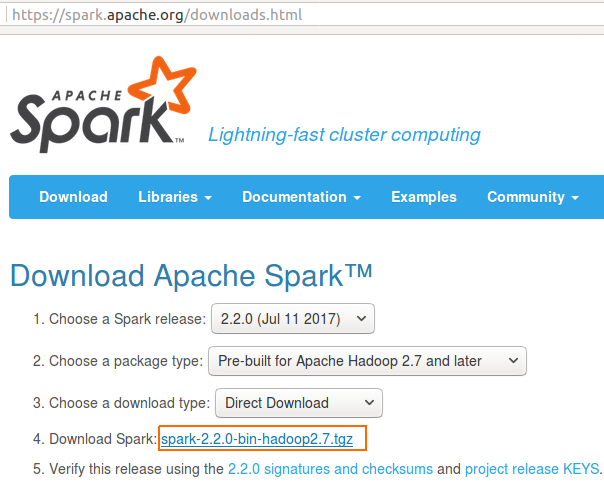
1. Download Apache Spark
Download Apache Spark from [https://spark.apache.org/downloads.html]. The package is around ~200MB. It might take a few minutes.
2. Unzip and find jars
Unzip the downloaded folder. The contents present would be as below :
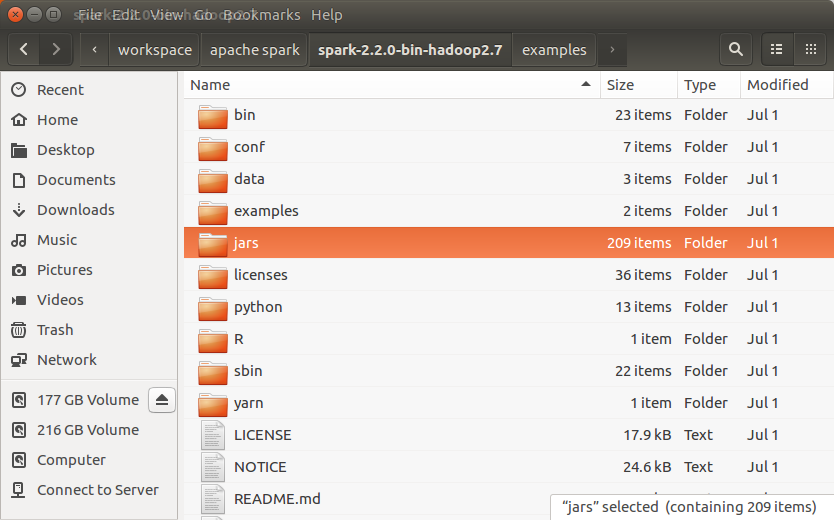
jars : this folder contains all the jars that needs to be included in the build path of our project.
3. Create Java Project and copy jars
Create a Java Project in Eclipse, and copy jars folder in spark directory to the Java Project, SparkMLlib22.
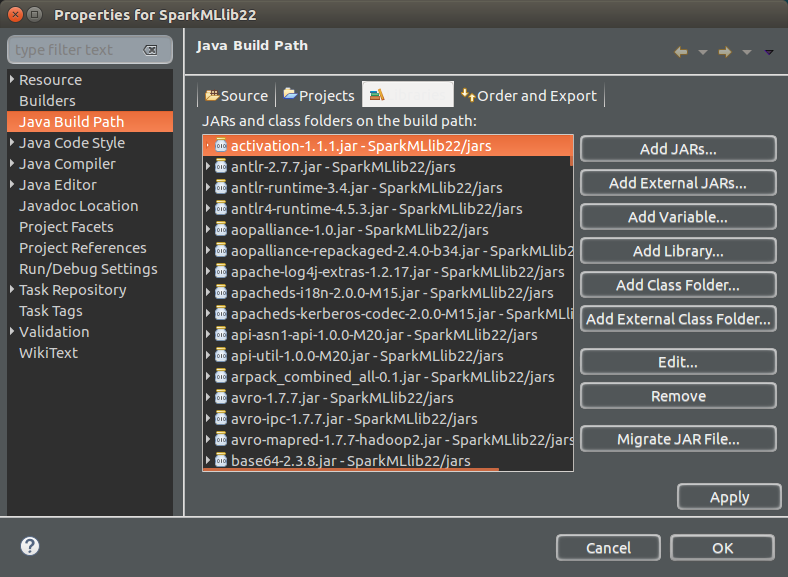
4. Add Jars to Java Build Path
Right click on Project (SparkMLlbi22) -> Properties -> Java Build Path(3rd item in the left panel) -> Libraries (3rd tab) -> Add Jars (button on right side panel) -> In the Jar Selection, Select all the jars in the ‘jars‘ folder -> Apply -> OK.
5. Check the setup – Run an MLLib example
You may also copy ‘data’ folder to the project and add ‘jars’ in spark ‘examples‘ directory to have a quick glance on how to work with different modules of Apache Spark. We shall run the following Java Program, JavaRandomForestClassificationExample.java, to check if the Apache Spark setup is successful with the Java Project.
JavaRandomForestClassificationExample.java
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
// $example on$
import java.util.HashMap;
import scala.Tuple2;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.mllib.regression.LabeledPoint;
import org.apache.spark.mllib.tree.RandomForest;
import org.apache.spark.mllib.tree.model.RandomForestModel;
import org.apache.spark.mllib.util.MLUtils;
// $example off$
public class JavaRandomForestClassificationExample {
public static void main(String[] args) {
// $example on$
SparkConf sparkConf = new SparkConf().setAppName("JavaRandomForestClassificationExample")
.setMaster("local[2]").set("spark.executor.memory","2g");
JavaSparkContext jsc = new JavaSparkContext(sparkConf);
// Load and parse the data file.
String datapath = "data/mllib/sample_multiclass_classification_data.txt";
JavaRDD data = MLUtils.loadLibSVMFile(jsc.sc(), datapath).toJavaRDD();
// Split the data into training and test sets (30% held out for testing)
JavaRDD[] splits = data.randomSplit(new double[]{0.7, 0.3});
JavaRDD trainingData = splits[0];
JavaRDD testData = splits[1];
// Train a RandomForest model.
// Empty categoricalFeaturesInfo indicates all features are continuous.
Integer numClasses = 3;
HashMap<Integer, Integer> categoricalFeaturesInfo = new HashMap<>();
Integer numTrees = 55; // Use more in practice.
String featureSubsetStrategy = "auto"; // Let the algorithm choose.
String impurity = "gini";
Integer maxDepth = 5;
Integer maxBins = 32;
Integer seed = 12345;
final RandomForestModel model = RandomForest.trainClassifier(trainingData, numClasses,
categoricalFeaturesInfo, numTrees, featureSubsetStrategy, impurity, maxDepth, maxBins,
seed);
// Evaluate model on test instances and compute test error
JavaPairRDD<Double, Double> predictionAndLabel =
testData.mapToPair(new PairFunction<LabeledPoint, Double, Double>() {
@Override
public Tuple2<Double, Double> call(LabeledPoint p) {
return new Tuple2<>(model.predict(p.features()), p.label());
}
});
Double testErr =
1.0 * predictionAndLabel.filter(new Function<Tuple2<Double, Double>, Boolean>() {
@Override
public Boolean call(Tuple2<Double, Double> pl) {
return !pl._1().equals(pl._2());
}
}).count() / testData.count();
System.out.println("Test Error: " + testErr);
System.out.println("Learned classification forest model:\n" + model.toDebugString());
// Save and load model
model.save(jsc.sc(), "target/tmp/myRandomForestClassificationModel");
RandomForestModel sameModel = RandomForestModel.load(jsc.sc(),
"target/tmp/myRandomForestClassificationModel");
// $example off$
jsc.stop();
}
}Output
17/07/23 09:46:09 INFO DAGScheduler: Submitting ResultStage 6 (MapPartitionsRDD[20] at map at RandomForest.scala:553), which has no missing parents
17/07/23 09:46:09 INFO MemoryStore: Block broadcast_8 stored as values in memory (estimated size 8.1 KB, free 882.2 MB)
17/07/23 09:46:09 INFO MemoryStore: Block broadcast_8_piece0 stored as bytes in memory (estimated size 3.4 KB, free 882.2 MB)
17/07/23 09:46:09 INFO BlockManagerInfo: Added broadcast_8_piece0 in memory on 192.168.1.100:34199 (size: 3.4 KB, free: 882.5 MB)
17/07/23 09:46:09 INFO SparkContext: Created broadcast 8 from broadcast at DAGScheduler.scala:1006
17/07/23 09:46:09 INFO DAGScheduler: Submitting 2 missing tasks from ResultStage 6 (MapPartitionsRDD[20] at map at RandomForest.scala:553) (first 15 tasks are for partitions Vector(0, 1))
17/07/23 09:46:09 INFO TaskSchedulerImpl: Adding task set 6.0 with 2 tasks
17/07/23 09:46:09 INFO TaskSetManager: Starting task 0.0 in stage 6.0 (TID 11, localhost, executor driver, partition 0, ANY, 4621 bytes)
17/07/23 09:46:09 INFO TaskSetManager: Starting task 1.0 in stage 6.0 (TID 12, localhost, executor driver, partition 1, ANY, 4621 bytes)
17/07/23 09:46:09 INFO Executor: Running task 0.0 in stage 6.0 (TID 11)
17/07/23 09:46:09 INFO Executor: Running task 1.0 in stage 6.0 (TID 12)
. .
. .Conclusion
In this Apache Spark Tutorial, we have successfully learnt to create a Java Project with Apache Spark libraries as dependencies; and run a Spark MLlib example program.