DAG (Directed Acyclic Graph) and Physical Execution Plan are core concepts of Apache Spark. Understanding these can help you write more efficient Spark Applications targeted for performance and throughput.
What is a DAG according to Graph Theory ?
DAG stands for Directed Acyclic Graph.
From Graph Theory, a Graph is a collection of nodes connected by branches. A Directed Graph is a graph in which branches are directed from one node to other. A DAG is a directed graph in which there are no cycles or loops, i.e., if you start from a node along the directed branches, you would never visit the already visited node by any chance.
What does a DAG mean to Apache Spark ?
Unlike Hadoop where user has to break down whole job into smaller jobs and chain them together to go along with MapReduce, Spark Driver identifies the tasks implicitly that can be computed in parallel with partitioned data in the cluster. With these identified tasks, Spark Driver builds a logical flow of operations that can be represented in a graph which is directed and acyclic, also known as DAG (Directed Acyclic Graph). Thus Spark builds its own plan of executions implicitly from the spark application provided.
Execution Plan of Apache Spark
Execution Plan tells how Spark executes a Spark Program or Application. We shall understand the execution plan from the point of performance, and with the help of an example.
Consider the following word count example, where we shall count the number of occurrences of unique words.
counts = sc.textFile("/path/to/input/")
.flatMap(lambda line: line.split(" "))
.map(lambda word: (word, 1))
.reduceByKey(lambda a, b: a + b)
counts.saveAsTextFile("/path/to/output/")Following are the operations that we are doing in the above program :
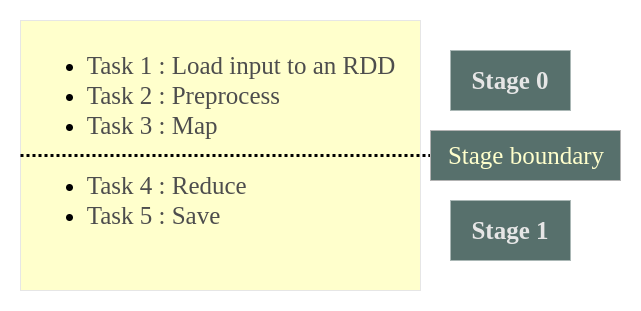
- Task 1 : Load input to an RDD
- Task 2 : Preprocess
- Task 3 : Map
- Task 4 : Reduce
- Task 5 : Save
It has to noted that for better performance, we have to keep the data in a pipeline and reduce the number of shuffles (between nodes). The data can be in a pipeline and not shuffled until an element in RDD is independent of other elements.
In our word count example, an element is a word. And from the tasks we listed above, until Task 3, i.e., Map, each word does not have any dependency on the other words. But in Task 4, Reduce, where all the words have to be reduced based on a function (aggregating word occurrences for unique words), shuffling of data is required between the nodes. When there is a need for shuffling, Spark sets that as a boundary between stages.
In the example, stage boundary is set between Task 3 and Task 4.
This could be visualized in Spark Web UI, once you run the WordCount example.
- Hit the url 192.168.0.104:4040/jobs/
- Click on the link under Job Description.
- Expand ‘DAG Visualization’
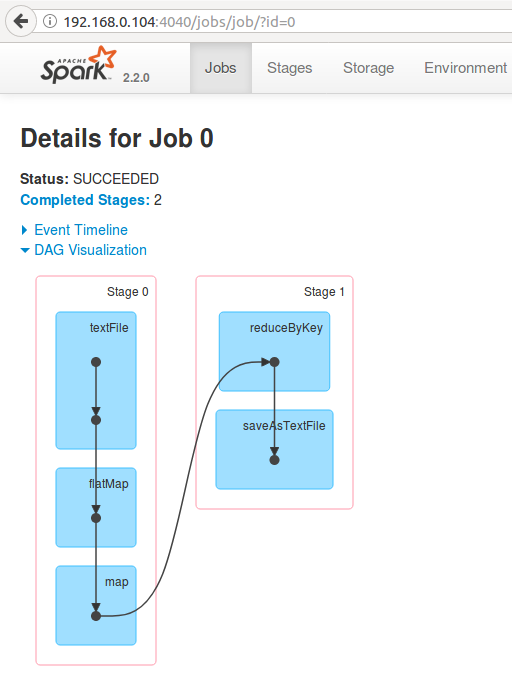
Tasks in each stage are bundled together and are sent to the executors (worker nodes).
How Apache Spark builds a DAG and Physical Execution Plan ?
Following is a step-by-step process explaining how Apache Spark builds a DAG and Physical Execution Plan :
- User submits a spark application to the Apache Spark.
- Driver is the module that takes in the application from Spark side.
- Driver identifies transformations and actions present in the spark application. These identifications are the tasks.
- Based on the flow of program, these tasks are arranged in a graph like structure with directed flow of execution from task to task forming no loops in the graph (also called DAG). DAG is pure logical.
- This logical DAG is converted to Physical Execution Plan. Physical Execution Plan contains stages.
- Some of the subsequent tasks in DAG could be combined together in a single stage.
Based on the nature of transformations, Driver sets stage boundaries.
There are two transformations, namely narrow transformations and wide transformations, that can be applied on RDD(Resilient Distributed Databases).
narrow transformations : Transformations like Map and Filter that does not require the data to be shuffled across the partitions.
wide transformations : Transformations like ReduceByKey that does require the data to be shuffled across the partitions.
Transformation that requires data shuffling between partitions, i.e., a wide transformation results in stage boundary. - DAG Scheduler creates a Physical Execution Plan from the logical DAG. Physical Execution Plan contains tasks and are bundled to be sent to nodes of cluster.