Configuring Apache Spark Ecosystem
There are some parameters like number of nodes in the cluster, number of cores in each node, memory availability at each node, number of threads that could be launched, deployment mode, extra java options, extra library path, mapper properties, reducer properties, etc., that are dependent on the cluster setup or user preferences. These parameters are given control over, to the Apache Spark application user, to fit or configure Apache Spark ecosystem to the Spark application needs.
We shall learn the parameters available for configuration and what do they mean to the Spark ecosystem.
Following are the three broad categories of parameters where you can setup the configuration for Apache Spark ecosystem.
- Spark Application Parameters
- Spark Environment Parameters
- Logging Parameters
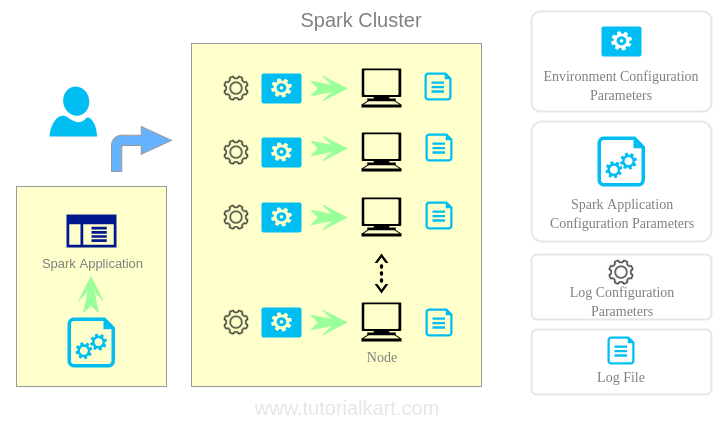
From the above figure :
- Spark Application Configuration Parameters are submitted to Driver Program by the user.
- Environment and Log Parameters are configured at worker nodes using shell script and logging properties file.
Spark Application Parameters
These parameters effect only the behavior and working of Apache Spark application submitted by the user.
Following are the ways to setup Spark Application Parameters :
- Spark Application Parameters could be setup in the spark application itself using
SparkConfobject in the Driver program. - They could also be set using Java system properties if you are programming in a language runnable on JVM.
- These parameters could also provided by the user when submitting the spark application in the command prompt using
spark-submitcommand.
Setup Application Parameters using SparkConf
SparkConf is used to set Spark application parameters as key-value pairs.
Following are some of the setters that set respective parameters :
| SparkConf Method | Description |
| setAppName(String name) | Set a name for your application. |
| setExecutorEnv(scala.collection.Seq<scala.Tuple2<String,String>> variables) | Set multiple environment variables to be used when launching executors. |
| setExecutorEnv(String variable, String value) | Set an environment variable to be used when launching executors for this application. |
| setExecutorEnv(scala.Tuple2<String,String>[] variables) | Set multiple environment variables to be used when launching executors. |
| setIfMissing(String key, String value) | Set a parameter if it isn’t already configured |
| setJars(scala.collection.Seq<String> jars) | Set JAR files to distribute to the cluster. |
| setMaster(String master) | The master URL to connect to, such as “local” to run locally with one thread, “local[4]” to run locally with 4 cores, or “spark://master:7077” to run on a Spark standalone cluster. |
| setSparkHome(String home) | Set the location where Spark is installed on worker nodes. |
All the above methods return SparkConf with the parameter set. Hence chaining of these setters could be done as shown in the following example.
SparkConf sparkConf = new SparkConf().setAppName("Spark Application Name")
.setMaster("local[2]")
.set("spark.executor.memory","2g");Spark Environment Parameters
These parameters effect the behavior and working and memory usage of nodes in the cluster.
To configure each node in the spark cluster individually, environment parameters has to be setup in spark-env.sh shell script. The location of spark-env.sh is <apache-installation-directory>/conf/spark-env.sh. To configure a particular node in the cluster, spark-env.sh file in the node has to setup with the required parameters.
Logging Parameters
These parameters effect the logging behavior of the running Apache Spark Application.
To configure logging parameters, modify the log4j.properties file with the required values and place it in the location <apache-installation-directory>/conf/log4j.properties. This can be done at node level i.e., logging properties for each node could be setup by placing the log4j.properties in the node at the specified location.
Conclusion
In this Apache Spark Tutorial, we have learned how to configure an Apache Spark Ecosystem.